学习指南
【性感的深度学习】系列
这个系列是几分钟到十几分钟的短视频,分成基础篇和进阶篇两部分,都是有梗有趣视角独特制作精良的干货,大量动画类比生动活泼容易理解。配合《破解深度学习》教材学习更到位哦!
基础篇
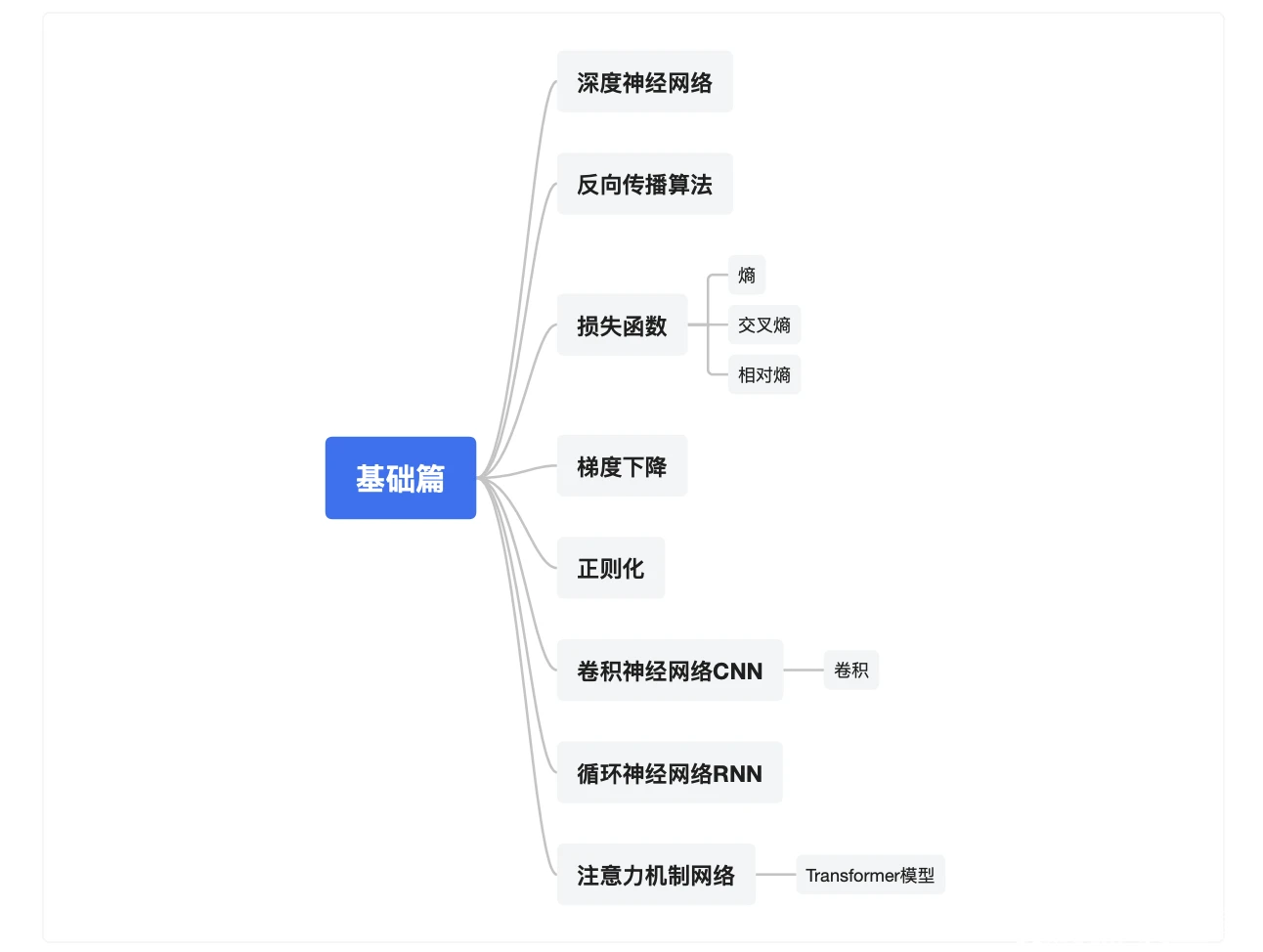
如果你是小白刚入门,先从基础篇开始学,可以快速弄懂什么是深度神经网络,反向传播算法的原理,损失函数(包括熵、交叉熵、相对熵等基础概念),训练最常用的梯度下降算法,正则化方法等核心概念,然后了解最基础的三种专用深度神经网络:卷积神经网络CNN、循环神经网络RNN和注意力机制网络Transformer模型。掌握了这些内容,你对什么是深度学习就有了一个大致的理解,好比能走马观花快速访问一座大楼一样。
进阶篇
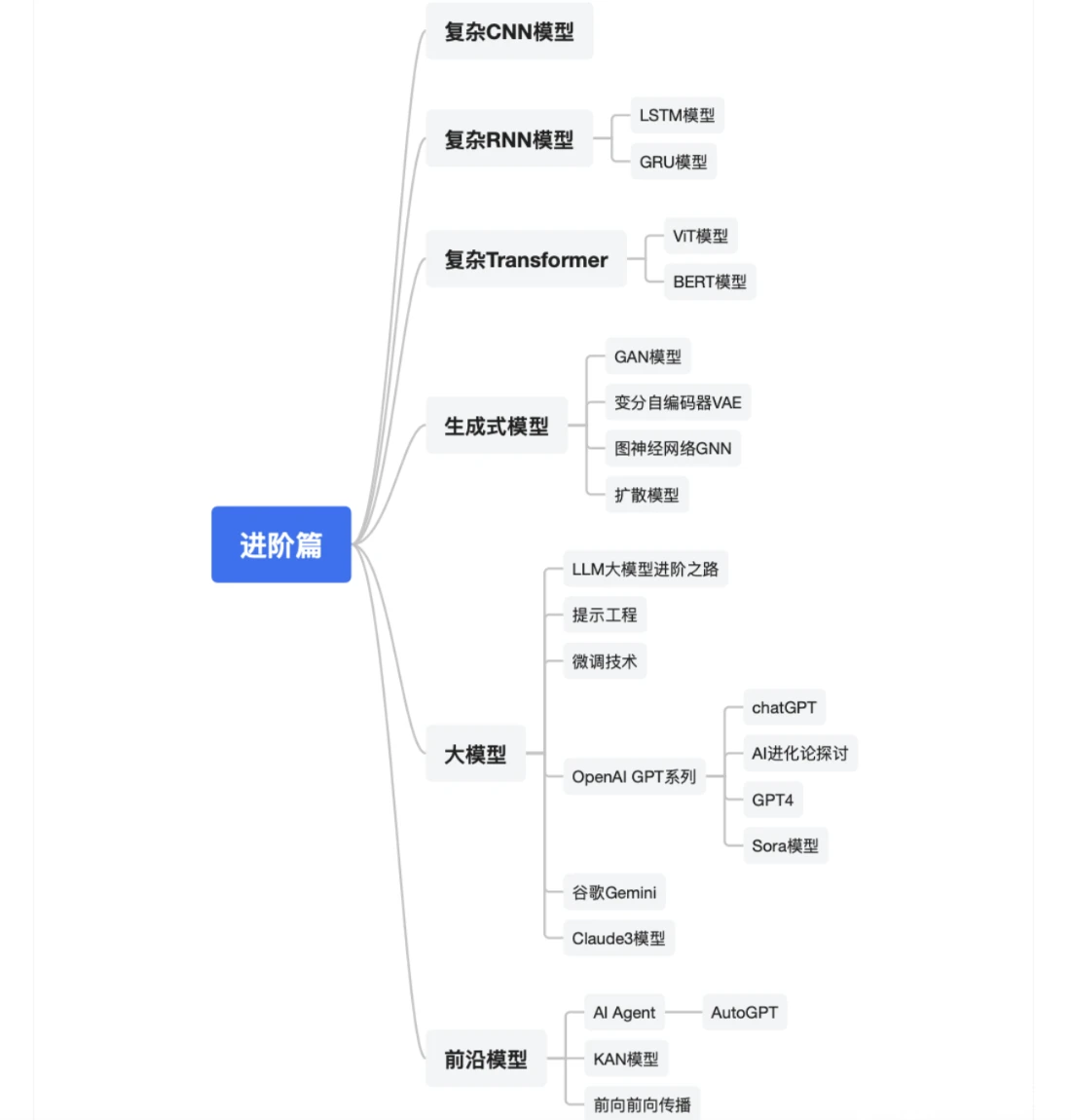
进阶篇包括了复杂CNN、RNN和Transformer模型。
复杂RNN我们重点讲解了LSTM模型、GRU模型,它俩大量用于时序数据的建模,比如自然语言处理等。复杂Transformer,我们讲解了用于图像处理ViT模型,自然语言处理的BERT模型。概率生成式模型方面,我们讲解了三类特别典型的:生成对抗网络、变分自编码器模型VAE、AI绘画密切相关的扩散模型,以及图神经网络GNN。
大模型方面的内容就比较多了,我们先高屋建瓴给出了一个大模型进阶之路,然后讲解了提示工程、微调技术,接着详细介绍了OpenAl的GPT系列,包括chatGPT、GPT4,以及Sora模型。另外,我们还介绍了对标公司谷歌的Gemini和Anthropic公司的Claude3模型。前沿模型方面我们介绍了非常有前景的AI Agent技术,包括典型的AutoGPT,也就是用大模型当大脑的AI机器人。然后介绍了最新的KAN模型,前向前向传播技术等新方向。
【AI论文精读】系列
深度学习
| 年份 | 名称(点击阅读原文) | 简介 | 引用量 | 讲解视频 |
|---|---|---|---|---|
| 经典模型 | ||||
| 2012 | AlexNet | 这一轮深度学习的发迹制作,经典论文 | 120124 | |
| 2014 | VGGNet | 早期典型的深度卷积网络,从几层跳到了十几层 | 100606 | |
| 2016 | ResNet | 目前引用最高,网络深度到达千层 | 194718 | |
| 1997 | LSTM | 最经典的RNN变体,序列数据建模大师 | 91059 | |
| 2017 | Transformer | 大模型的基础网络 | 132795 | |
| 2015 | Batch Normalization | 训练神经网络秘方,缓解过拟合,数据整理 | 43366 | |
| 2014 | Dropout | 提升网络训练效率及缓解过拟合秘方 | 39910 | |
| 复杂模型 | ||||
| 2019 | BERT | 典型的Transformer大模型 | 95366 | |
| 2020 | Diffusion | AI绘画的基础 | 18419 | |
| 2021 | LoRA | AI绘画时代提升模型效率秘方,后来成了AI绘画风格迁移的代名词 | 10563 | |
| 2023 | Segment Anything | 大模型做分割的典型代表,用途广广 | 7424 | |
| 大模型 | ||||
| 2023 | GPT4 | GPT4最全面的解释 | 14789 | |
| 2022 | DiT | SORA视频生成的核心模型 | 2438 | |
| 高维可视化 | ||||
| 2008 | tSNE | 高维数据可视化最流行算法之一 | 42020 | |
| 2018 | UMAP | 高维数据可视化最流行算法之二 | 9501 | |
| 前沿模型 | ||||
| 2024 | KAN | 颠覆式创新,瞄准整个深度学习大厦的根基模块MLP进行替换 | 577 | |
| 2023 | Mamba | Transformer极具革命性的平替,开拓了AI界研究大模型的思路 | 2796 | |
| 2024 | Mamba Out | Mamba系列的第二篇 | 58 | |
| 2024 | Mamba2 | Mamba模型的改进版本 | 536 | |
| 2024 | TTT | 对Transformer有很大改进 | 112 | |
| 2024 | xLSTM | 非常值得关注和学习的重要架构 | 191 | |
强化学习
| 年份 | 名称(点击阅读原文) | 简介 | 引用量 | 讲解视频 |
|---|---|---|---|---|
| DQN系列 | ||||
| 2013 | DQN | 首次使用深度网络结合Q-learning学习控制策略 | 12264 | |
| 2015 | DDQN | 有效降低DQN在Atari环境中对动作价值的过估 | 7662 | |
| 2016 | Dualing DQN | 动作值函数拆分成状态值和动作优势 | 3768 | |
| 策略梯度方法 | ||||
| 2015 | DDPG | 将确定性策略梯度与深度网络结合 | 13285 | |
| 2018 | TD3 | 引入延迟策略更新等机制进一步优化DDPG | 5211 | |
| 经典Actor-Critic方法 | ||||
| 2016 | A3C | 异步并行架构加速训练 | 8879 | |
| 2018 | SAC | 基于最大熵的策略迭代框架 | 8406 | |
| PPO系列 | ||||
| 2015 | TRPO | 引入信赖域约束策略更新 | 6796 | |
| 2017 | PPO | 最广泛应用的强化学习方法之一 | 19265 | |
| 2023 | DPO | 基于偏好数据隐式学习奖励模型 | 4139 | |
| 2024 | GRPO | 根据群体得分估计基线 | 1274 | |
| 2025 | DAPO | 引入解耦裁剪、动态采样等机制 | 215 | |
| 多智能体 | ||||
| 2017 | MADDPG | 多智能体环境实现集中式Critic和分散式Actor架构 | 4509 | |
| 2021 | MAPPO | PPO在多智能体环境同样可以取得良好效果 | 1271 | |




